开源大模型领域的进化节奏,越来越快。
今年 7 月,Meta 开源了 LLaMA2,以强大的性能和免费商用的特质,受到了开发者和众多企业的拥护。基于 LLaMA2 各个版本微调的落地成果不断涌现,大模型领域的竞争格局迅速发生变化。
业界普遍认为,在开源大模型的攻势下,一部分闭源大模型厂商的「护城河」将慢慢瓦解。难以负担大模型 API 高昂调用成本的中小企业和开发者,有了另一条更具性价比的出路。
与此同时,国产大模型开源力量也在技术上不断追赶加速。
近日,一项重磅开源吸引了领域内的高度关注:昆仑万维大语言模型「天工」Skywork-13B 系列正式宣布开源。
之所以说是「重磅」,是因为Skywork-13B 不仅在 C-Eval,MMLU 等基准测试上全面超越了 LLaMA2-13B,而且这次开源范围包括了 Skywork-13B-Base 模型、Skywork-13B-Math 模型以及每个模型的量化版模型。此外,昆仑万维还同时开源了 600GB、150B Tokens 的高质量中文语料数据集「Skypile/Chinese-Web-Text-150B」。昆仑万维还宣布,Skywork-13B 系列大模型将全面开放商用 —— 开发者无需申请,0 门槛商用。
Skywork-13B 下载地址(Model Scope):https://modelscope.cn/organization/skywork
Skywork-13B 下载地址(Github):https://github.com/SkyworkAI/Skywork
技术报告地址:https://arxiv.org/pdf/2310.19341.pdf

昆仑万维董事长兼 CEO 方汉在云栖大会 AI 大模型新势力分论坛现场分享 Skywork-13B 系列大模型开源与 AI 场景应用落地
国产开源大模型全面赶超之路
这次 Skywork-13B 系列的发布,可以说是国产开源大模型的又一力作。
Skywork-13B-Base 模型基于高质量清洗过滤的 3.2 万亿个多语言(主要是中文和英文)和代码数据的训练,在多种评测和各种基准测试上全面超越了 LLaMA2-13B 等开源大模型,在同等参数规模下为最优水平。
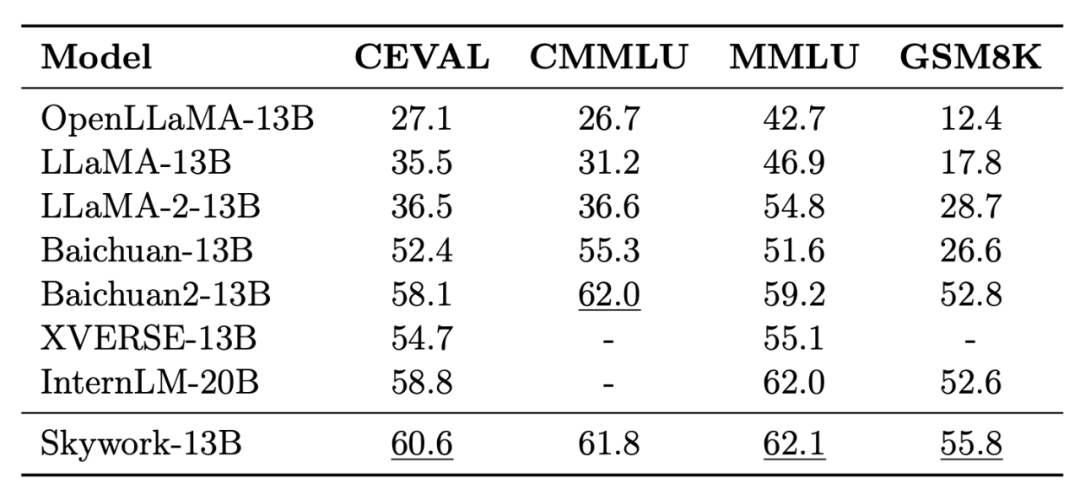
评测 Benchmark 包括 C-Eval,MMLU,CMMLU,GSM8K。遵循之前的评估流程,C-Eval、MMLU、CMMLU 测试 5-shot 结果,GSM8K 测试 8-shot 结果。可以看到,Skywork-13B-Base 模型在中文开源模型中处于前列,多项测评为同等参数规模下为最优水平。截止至 10 月 25 日数据。
对于密切关注大模型领域进展的人来说,上述与 Skywork-13B 进行对比的开源大模型系列的名字并不陌生。
过去一段时间里,各个系列开源大模型版本迭代让人应接不暇。这是一场火热的开源竞逐,对于整个大模型领域有着绝对的积极意义。
任何一个技术领域的生态构建,前沿技术的普及与真正落地,都离不了开源社区的力量。知识的共享、交流、碰撞,反过来也会加速技术的创新和商业化落地,让人们享受到更多 AI 技术带来的革新体验。
昆仑万维向本站表示,Skywork-13B 系列大模型的开源,正是希望让更多开发者们参与到 AIGC 的技术发展中,在共创和共享中推动技术的提升。
事实上,自大模型概念诞生之初,「开源」和「闭源」两条路线就同时存在,只不过二者所指向的资金、人才和商业模式的理念截然不同。
五年前,OpenAI 开始 GPT 系列研发的时候,也曾是开源路线的坚定拥护者。不过这家公司逐渐走向了封闭,以至于今天我们都无从求证 ChatGPT 背后是多少参数量的模型。
紧跟其后的谷歌同样只公布了一篇未透露任何关键信息的 PaLM-2 技术报告,被誉为「OpenAI 最强竞对」的 Anthropic 更是直接选择不发布 Claude 技术报告。
既然「OpenAI 们」不再「Open」,除了「重新造轮子」这个选项之外,人们的目光迅速转向开源的力量。
大模型开源,仍存在「三大痛点」
选择加入这场开源大模型的竞争,并不是昆仑万维「临时起意」。
昆仑万维董事长兼 CEO 方汉是最早参与到开源生态建设的「开源老兵」,也是中文 Linux 开源最早的推动者之一。
作为「开源老兵」,方汉判断,当前,大模型开源至少还有三大痛点:
1、中文数据极其稀缺与宝贵
2、模型训练细节不公开
3、模型开源面临诸多商用限制
比如 LLaMA2 这样的开源大模型,仅发布了原始模型权重与推理脚本,不支持训练 / 微调,也未提供数据集,且训练数据里中文语料仅占 0.13%,更不用说复杂的「可商用协议」了。
方汉曾向本站表示,LLaMA2 开源并没有对外披露数据层的具体信息,因此复现 LLaMA2 成为一件受限制的事情。「比如一座楼房,你只能在这个基础之上去装修却做外设,但是你没有办法去改变它的钢混结构,你没有训练它底座的权限和能力,所以它的性能很难突破,逼近 GPT-4 这个事情是不可能的。」
对开源大模型有需求、也真正接触过此类开源大模型的人大概都能感受到,这样做的结果就是:开源了,但没完全开源。
国产开源大模型的赶超,完全可以从上述三个痛点入手。
首先,数据的质量会对大模型的性能起到至关重要的作用,有了足够多的可公开访问的网络数据,更容易训练出高质量的大语言模型。正因此,很少有大模型厂商会将其共享出来,而清洗好的中文数据更是眼下的稀缺资源。
在构建 Skywork-13B 的过程,昆仑万维整理了一个超过 6 万亿个 Token 的高质量语料库「SkyPile」。训练完成后,他们精选出一个 600GB、150B Tokens 的高质量中文语料数据集 Skypile/Chinese-Web-Text-150B,包含大量根据精心过滤的数据处理流程从中文网页中筛选出的高质量数据,直接公开发布。
这也是目前最大的开源中文数据集之一。关于「Skypile/Chinese-Web-Text-150B」的数据收集方法和过程,昆仑万维在技术报告中进行了详细介绍,供所有研究者和从业者参考。
其次,昆仑万维还公开了训练 Skywork-13B 模型使用的评估方法、数据配比研究和训练基础设施调优方案等技术细节。
在训练方法上,为了更加精细化利用数据,Skywork-13B 开源系列模型采用了两阶段训练方法,第一阶段使用通用语料进行模型通用能力学习,第二部分加入 STEM(科学,技术,工程,数学)相关数据进一步增强模型的推理能力、数学能力、问题解决能力。
在模型结构上,Skywork-13B 模型采用相对 LLaMA2-13B 更加瘦长的网络结构,层数为 52 层,同时将 FFN Dim 和 Hidden Dim 缩小到 12288 和 4608,从而保证模型参数量和原始 LLaMA-13B 模型相当。根据前期实验,相对瘦长的网络结构在大 Batch Size 训练下可以取得更好的泛化效果。
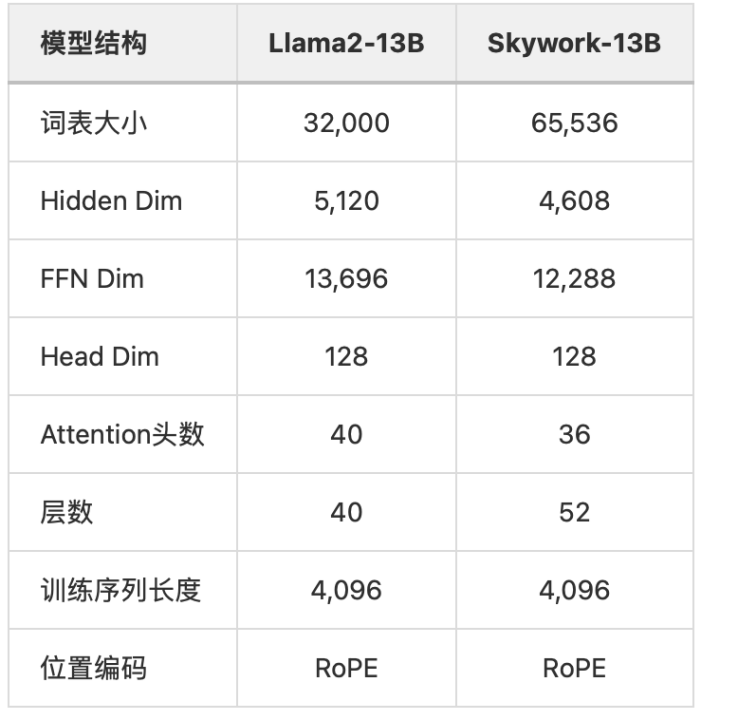
Skywork-13B 和 LLaMA-2-13B 模型的对比。
如此一来,开发者可以最大程度地借鉴技术报告中大模型预训练的过程和经验,深度定制模型参数,有针对性地进行训练与优化。
更关键的一点便是「可商用协议」,领域内寄希望于开源大模型加速商业化落地,但现在开源社区用户通常需要进行复杂的商用授权申请流程,在某些情况下,甚至对公司规模、所在行业、用户数等维度有明确规定不予授权。这似乎与开源的宗旨背道而驰了。
而 Skywork-13B 系列在商用层面制定的规则是「没有限制」—— 全面开放,开发者无需额外申请,即可直接商用。
用户在下载模型后同意并遵守《Skywork 模型社区许可协议》后,不必再次申请授权即可将大模型进行商业用途。
这种彻底的开源行为在行业内十分少见,将授权流程做到极简,取消对行业、公司规模、用户等方面的限制,足以看出昆仑万维以 Skywork-13B 系列推动开源社区发展的决心。
开源大模型跨过商用门槛,推动生态繁荣
大模型时代的序幕已拉开,就像今天的水电煤一样,大模型会成为未来社会的基础设施。
模型开源能够帮助用户简化模型训练和部署的过程,使其不必从零开始训练,只需下载预训练好的模型进行微调,就可快速构建高质量的模型。
更进一步说,开源大模型能够降低企业和开发者的研发门槛和使用成本,最大化共享技术能力和经验,让更多人参与到 AI 引领的科技变革中去。
自从 LLaMA2 之后,开源大模型的实力跨越了商用门槛,已经能够与闭源大模型相抗衡。而 Skywork-13B 系列的面世,让用户有了一项更好的选择。
在方汉看来,技术本身会快速迭代演进,只有开源才能满足各种长尾需求,真正做到百花齐放,而不会出现由大型互联网公司独霸 AI 基础设施的局面。
当然,想要做好开源不仅仅依靠决心,还需要深厚的实力做底牌。

昆仑万维董事长兼 CEO 方汉在云栖大会 AI 大模型新势力分论坛现场分享 Skywork-13B 系列大模型开源与 AI 场景应用落地
凭借对科技发展趋势的超前预判,昆仑万维早在 2020 年便已开始布局 AIGC 领域。至今,已积累近三年的相关工程研发经验,并建立了行业领先的预训练数据深度处理能力,昆仑万维也在人工智能领域取得了重大突破,目前已形成 AI 大模型、AI 搜索、AI 游戏、AI 音乐、AI 动漫、AI 社交六大 AI 业务矩阵,是国内模型技术与工程能力最强,布局最全面,同时全身心投入开源社区建设的企业之一。
在北京市经济和信息化局公布的《北京市通用人工智能产业创新伙伴计划成员名单》中,昆仑万维凭借在 AIGC 领域的前沿探索和投资布局,成为了第一批模型伙伴和投资伙伴。
回望过去一年,大模型的热潮最初由 ChatGPT 开始,却因 LLaMA2 等开源成果的出现走到了一个更加好用、易用的时代。开源与闭源大模型在互相竞争,实质上也是在相互促进,共同推进了大模型生态的繁荣。